
The Data-Driven Community Meetup holds monthly webinars on business analytics and big data. Webinars are held on the second Wednesday of the month at noon (12:00 PM) central time via Zoom Webinars and will cover topics related to enterprise data management. Our goal with each webinar is to provide meaningful insights and actionable takeaways to simplify analytics so you can make better decisions.
The topics we cover include data strategy, data management, data warehousing, BI modernization, embedded analytics, and cloud migration and strategy. Learn how to build reporting solutions that drive your business demand based on your needs.
About the Topic
President at XeoMatrix, Chris Monahon, and Client Success Manager, Stuart Tinsley, recently held a meetup titled “Data Lakes and Data Pipelines” to demonstrate how to leverage a Data Lake and Data pipelines to source the data you need from your on-premise systems and the cloud.
This article includes a recording, transcript, and written overview of the Data Lakes and Data Pipelines presentation.
Presentation Video
Summarized Presentation
In the contemporary digital landscape, the ubiquity of data sources is undeniable. Businesses today face the challenge of managing data dispersed across multiple on-premises and cloud platforms, making data consolidation a daunting task. To tackle this, the integration of data lakes and data pipelines becomes pivotal. A data lake acts as a central repository, storing vast quantities of raw data in its native format. This contrasts traditional databases and offers versatility for unforeseen future uses. The data landscape further includes data warehouses, known for their structured nature, and ‘lake houses,’ a hybrid solution marrying the advantages of both lakes and warehouses. On the other hand, data pipelines function as channels that transport data from varied sources into centralized storage, enabling seamless data movement and pre-processing for diverse applications.
Navigating through this data-centric environment, it’s essential to comprehend the architecture of integrating various data sources. Envisioning a typical system, data pipelines play a crucial role, acting as bridges between diverse sources such as Oracle, Salesforce, or flat files and central storage solutions like Snowflake or BigQuery. Once ingested, the data resides in a lake, primed for processing and reporting in analytical tools, such as Tableau. One can’t overlook the importance of API connections in this blueprint, as they offer tailor-made connectors to funnel data into the centralized repository. Moreover, while platforms like Salesforce might natively integrate with Tableau, the performance often improves significantly when data converges in a centralized hub like a data lake.
When deciding on a tech stack for this complex setup, businesses are presented with a plethora of choices. Crucial considerations span from determining the hosting environment (on-premises vs. cloud) to understanding cost structures and gauging platform performance. Security, compliance, and ease of use also emerge as vital parameters. Pivoting towards data pipelines, priorities remain consistent, with a strong emphasis on performance, scalability, and connector utility. Purchasing decisions in this domain demand a strategic approach. Organizations should meticulously identify all data sources, delineate essential requirements, and ideally test 2-3 vendors during a trial phase. Assessing costs, considering pre-purchasing credits, and understanding maintenance implications are key financial strategies. Furthermore, equipping the team with apt training ensures they’re well-prepared to exploit the new system’s capabilities, enabling businesses to thrive in their data management pursuits.
Presentation Outline
The session follows this outline.
Data Lakes and Data Pipelines
- Overview: What are Data Lakes and Data Pipelines
- What are the Benefits
- Evaluating a Tech Stack
- Purchasing Recommendations
Overview
Today’s Challenge
In today’s digital age, we are inundated with vast amounts of data. Almost everything we own and interact with, from our phones to our televisions, constantly generates data. For businesses, this data proliferation translates to multiple data sources across various departments, each contributing to pivotal decision-making processes.
However, a significant challenge arises with the rapid shift to cloud computing. Businesses often grapple with data scattered between on-premises systems and various cloud platforms. Consolidating these diverse data sources can be daunting. To address this, one must consider the integration of data lakes and data pipelines, offering a unified perspective of the entire business landscape.
What are Data Lakes?
A data lake is a centralized repository designed for storing vast volumes of raw data. Unlike traditional databases that might preprocess data based on business rules, data lakes allow users to deposit data ‘as is,’ effectively archiving it for future use.
This approach provides flexibility as organizations might not always immediately know the potential uses of the data, but they can store it for future insights or possible requirements. Within a data lake, the data can range from structured forms, like database tables or Excel sheets, to semi-structured forms, such as XML files, or even entirely unstructured data, like images, audio recordings, tweets, or other social media content.
Data Lakes vs. Data Warehouses vs. Data Lakehouses
Data lakes, data warehouses, and the emerging concept of ‘lake houses’ are all terms you may have come across in the realm of data storage. While data lakes offer flexibility to accommodate various forms of data, including structured, semi-structured, and unstructured, they stand out for their adaptability to relational and non-relational data. In contrast, a data warehouse is more rigid, focusing on curated data structured by business rules. This design aids analytics and reporting, but it can be high maintenance, costly, and sometimes prone to quality-control challenges due to data transformation.
Enter the ‘lake house,’ a hybrid solution gaining traction. It combines the raw data storage capabilities of a data lake with a structured reporting layer. This dual system allows for agile data exploration without duplicating data into separate databases. Consequently, data scientists can delve into raw data, while the BI team uses a more structured approach, effectively harnessing the strengths of both worlds.
What are Data Pipelines?
Data pipelines serve as pathways for collecting and transporting data from diverse sources into centralized storage solutions like data lakes, warehouses, or the emerging ‘lake houses.’ Essentially, they are the conduits that enable the movement and central storage of data. These pipelines can also transform raw data, making it ready for varied applications, from analytics to machine learning and AI.
A notable feature of data pipelines is their adaptability; there’s a multitude of supported connectors and pipeline types. While some are backed by specific vendors, others can be custom-crafted, often using API methods. The importance of these pipelines lies in their role as the primary tools for data aggregation and centralization in a lake house.
What are the Benefits
Why should one invest in data centralization, and what are its benefits? Many users of platforms like Tableau frequently grapple with disparate data sources. While Tableau’s data blending feature is commendable for its flexibility and speed, it’s not without limitations, especially concerning data volume and potential performance impacts.
Centralizing data, such as in a data lake or lake house, is advantageous for several reasons. Firstly, it offers the chance to aggregate raw data in a singular location, which in turn boosts agility. Instead of grappling with intricate requirements at a project’s onset, users can collate data first and then delve into its specifics when sculpting their reporting layers. This process cuts down initial building time for the data lake, subsequently offering a nimble approach that demands less maintenance than traditional data warehouses.
One tangible outcome is expedited insights. The reduced need for blending in platforms like Tableau means users can craft dashboards at a swifter pace, eliminating common struggles like problematic data joins. In essence, merging the strengths of data lakes with data pipelines enhances flexibility, reduces maintenance, and streamlines data utilization.
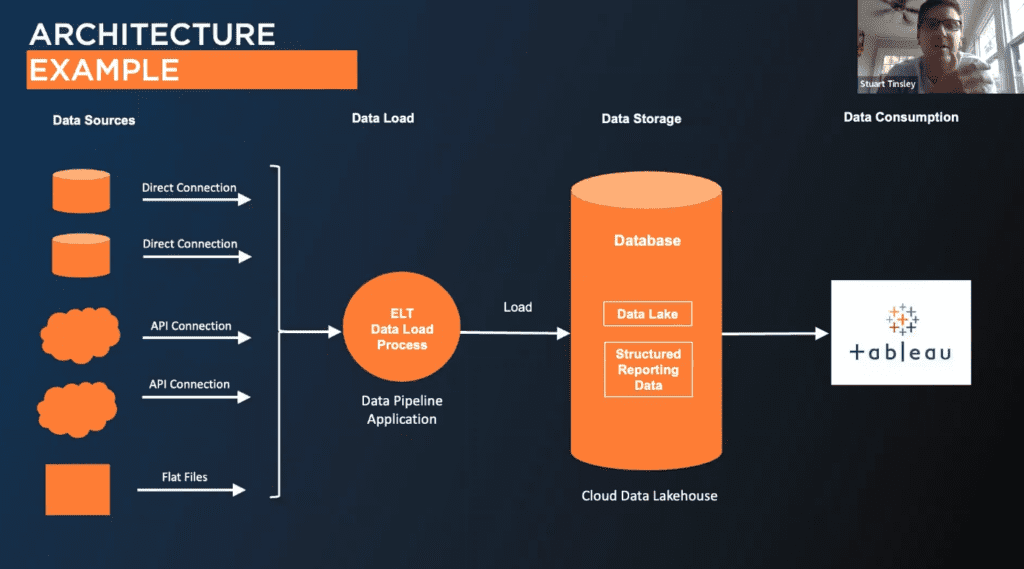
Architecture Example
In discussing data lakes and data pipelines, it’s helpful to visualize an example architecture. Spanning from left to right, the architecture encompasses diverse data sources, a data load process, storage, and finally, data consumption in Tableau’s reporting layer. These data sources vary widely, ranging from on-premises systems like Oracle or Teradata cloud-based platforms such as Salesforce to simple flat files or extracts sourced from third-party vendors via SFTP sites.
Data pipelines, which can be custom scripts or vendor-specific tools (discussed later), play a pivotal role in consolidating these sources. They ingest data into central databases, with the current trend favoring cloud solutions like Snowflake, Databricks, and BigQuery. The data then settles in a data lake, ready for processing and reporting in tools like Tableau.
This highlights the importance of API connections in this architecture. While common platforms like NetSuite, QuickBooks, and Salesforce often find ready connectors in third-party pipeline tools, there are always unique applications demanding custom solutions. APIs emerge as invaluable in these scenarios, allowing the creation of tailored connectors to flow data into the lake.
Salesforce emphasizes that while it might offer seamless connectivity with Tableau out of the box, performance enhancements and scalability are often achieved when data is consolidated in a centralized repository like a data lake.
Tech Stack Options
With an array of vendors in the market, the selection process for a tech stack may seem overwhelming. While many solutions are now cloud-based, some offer hybrid capabilities, catering to both on-premises and cloud needs. Here are crucial considerations when evaluating a tech stack:
- Hosting & Cloud Adoption: Determine where the database will reside—on-premises or cloud. Despite the prevailing cloud trend, some businesses have valid reasons for retaining data in-house.
- Cost & Pricing Structure:
- Grasp the overall pricing mechanism, considering factors like system maintenance.
- Modern pricing strategies prioritize compute and storage variables. However, compute costs, if not managed efficiently, can escalate rapidly.
- Balancing compute costs against platform utility is essential. Some organizations prioritize ease of use over cost due to specific operational patterns.
- Performance & Scalability: It’s vital to gauge whether the chosen solution can meet Service Level Agreements (SLAs) and accommodate future data expansion.
- Security & Compliance: Align the solution with existing security protocols. Given the ubiquity of compliance requirements like HIPAA, ensure that the platform encrypts data and adheres to stipulated standards.
- Ease of Use & Training: Transitioning to a new platform necessitates employee training. Determine the platform’s learning curve and the timeframe required for proficiency.
Shifting focus to data pipelines:
- Performance, Scalability & Ease of Use: These remain consistent priorities.
- Connector Utility & Support:
- Ascertain the variety and nature of connectors provided by the vendor.
- Analyze the robustness and historical performance of the connectors. Consider both community and vendor-supported options.
- Evaluate the possibility of integrating custom connectors, especially for unique data sources.
- Vendor Support & SLAs: Ensure the vendor offers reliable technical support with acceptable SLAs, particularly in crisis scenarios.
- Cost & Pricing Modalities: Much like data lakes, data pipelines also vary in pricing structures. Some charge based on compute while others bill based on data record numbers. Understanding these nuances is paramount to prevent unexpected cost escalations.
Purchasing Recommendations
When considering purchasing decisions in the realm of data management, we offer a systematic approach to streamline the process. Begin by meticulously identifying all your current and potential future data sources. This includes familiar platforms like NetSuite and Salesforce, as well as any prospective sources that might be on the horizon. A comprehensive list will be instrumental in assessing a vendor’s connector portfolio, ensuring compatibility with current and future needs.
Simultaneously, delineate the essential requirements from both a technical and business standpoint. This would encompass key service level agreements (SLAs), as well as specific needs related to data refresh times and frequencies. These factors invariably impact the cost, making it crucial to capture them accurately. Based on this collated information, we advise shortlisting two to three vendors for a trial phase. Most vendors extend the facility of a trial, and given that many base their pricing either on compute power or the volume of data transferred, this phase offers a valuable glimpse into daily data volumes and associated costs. Such trials not only illuminate future costs but also allow organizations to budget more effectively for the forthcoming year.
Another savvy financial strategy is to consider pre-purchasing credits, especially when the costing is compute-centric. Procuring these credits in advance often yields discounts, making it essential to discuss and comprehend these discount models with prospective vendors. Alongside the pricing structure, another critical aspect to factor in is the maintenance cost, which extends beyond mere system maintenance to include human resources. Assessing how many resources, in terms of personnel, would be required for the new platform is vital.
The evolution of data pipelines has ushered in an era of efficiency, particularly for smaller organizations. Contrasting today’s streamlined processes with the past, where a dedicated team was mandatory for data pipeline management, contemporary tools offer point-and-click simplicity. Such advancements translate to substantial savings in terms of both time and human resources, thereby underscoring the benefits of transitioning to these modern solutions.
To ensure a smooth purchasing process, always approach it with a detailed project plan, encapsulating the deployment timeline. Equipping your team with appropriate training and certifications is equally pivotal, ensuring they have the requisite skills to harness the full potential of the new system. With these steps in place, deployment should be seamless, positioning organizations for success in their data management endeavors.
Transcript
>> STUART TINSLEY: Welcome, everyone, to our Data-Driven Meetup, and this is our fifth session that we have done and recorded. Might be our 6th, but we’re really excited to go over a really important topic on data lakes and data pipelines. I’ll quickly go through our agenda for today. We’ll first discuss the meeting format, upcoming events for our Data-Driven Meetup. We’ll introduce our speakers today, and then our presentation will be on data lakes and data pipelines.
Like every session we have, we’ll end with Q&A panel discussion. So we want to encourage everyone to ask any questions that you have. We’ll make it interactive, and I want to make sure we get to every question.
Yes, meeting format today. Just a reminder that this is a virtual meeting, so please observe customary Zoom webinar etiquette. We certainly encourage you to participate in the chat window, so make any comments, send any questions for the speaker in that chat window. We will, of course, be holding a Q&A session after the presentation, and then a link of the recording for today’s webinar and any content will be sent out via email. We’ll also send out a short follow-up survey via email to help us improve our event. So if you get that survey, please take just a minute, fill it out. We want to get better at these Data-Driven Meetup sessions, and we’d love your feedback.
All right, so let’s talk about some upcoming events. So we hold these Data-Driven Meetups once a month, and our next session will be on the 13th of September at noon, central time. This will be a great session. This will be “Ten Tips and Tricks for Polishing Your Tableau Dashboards.” So we’ll go over the best practices that you can follow for building a really well-designed Tableau dashboard in that 45-minute presentation. Subsequent to that, we have some more events coming up for the DDC. That’ll be October 11th, November 8th and December 13th. So lots of sessions that are coming each month. I hope you can join these in the future.
All right, Just a reminder too, that Salesforce , they every year, have a gigantic conference they call Dreamforce. If you haven’t heard of it, there’s still time to sign up. That’ll take place September 12th, the 14th, and we’ve included the link down below if you want to register. Tableau has obviously a big footprint at Dreamforce, so just a reminder that it’s still accessible, and you could still grab a ticket for that.
All right, so I will turn it to Chris, our featured speaker today. He’s going to be talking about data lakes and data pipelines. Chris, over to you.
>> CHRIS MONAHON: All right. Thanks, Stuart. Welcome everyone. Thanks for tuning in today. Great to see a lot of familiar faces. For those that don’t know me, I’m Chris Monahon, president of XeoMatrix. We’re a Tableau Gold Partner based here in Austin, Texas. I have about 20 years in data analytics, data warehousing.
Today I’m going to be talking to you about data lakes and data pipelines. Stuart, who’s also our director of sales and client success, he sees a lot of questions around this from clients as well. So between the two of us, we’ll try to demystify a lot of what is a data lake and what is a data pipeline.
Probably one of the most popular questions we get from our Tableau clients is, “What’s a good data strategy for us?” “We hear about these data lakes and data pipelines. We have all these disparate data sources. How do we connect all this stuff together? And how do we even get started with something like a data stack?” So what we decided today was to put together a presentation that demystifies all of that and simplifies it down into terms that really lays out, what is a data lake? What’s a data pipeline? Why is that beneficial to you and your organization? How do you go about even evaluating a tech stack? There’s just so many vendors out there today. And then what are the recommendations for making a wise purchase? And then, like Stuart said, we’ll open it up to a Q&A session.
So let’s start off with a quick overview. As I mentioned, probably the most popular question we get from Tableau clients and all of our clients is that we have so much data. Data is everywhere today. It’s plentiful. Everything you have and own creates data. Your phone creates data. Your TVs create data. Everything creates data nowadays. And when it comes to your business, you most likely have many, many data sources that your business and different departments use every day to make very important decisions.
One of the challenges with that, especially now that everything has moved to the cloud, is that now you have some stuff that are on-prem internally, you have stuff that’s in the cloud, all these different data sources that you need to consolidate, and it’s just hard to do. So how do you get a unified view of your business? Well, that’s where data lakes and data pipelines come in.
So what is a data lake? You guys might have heard this. It’s simply just a centralized repository where you can store large volumes of raw data. So you’re storing your data, you can process it there, and keep it secure. Now, the key there is that it’s raw data. You’re not transforming it in any way according to certain business rules, you are essentially parking your data as is, and archiving it historically, and keeping it there for later use, maybe for a rainy day. You’re not really quite sure what you’re going to do with it, but you have it. And so that data can be, as I mentioned, very structured. It could be some database tables or something from Excel, as small as that. Or it could be like semi-structured, like XML files. Or it could be unstructured data, like image files, or audio files, or, Tweets, or something from social media. So all those types of different data sources and structures are supported by a data lake.
Now, if you’ve heard of data lakes, you’ve probably also heard of some other terms, like a data warehouse. Even the term nowadays, it’s starting to become popular: lake house. And the question was, what’s the difference between all these? Why would I want to use one versus the other? What’s the different approaches? What are they? If you think of it like this, your data lakes, again, support different types of structured data. Structured, semi-structured, unstructured data. And a data lake is going to be more flexible in nature, so you can have both relational and non-relational data in your data lake.
When it comes to a data warehouse, that data is going to be more curated. It’s going to be structured by some business rules that come from talking to the business and the reporting and analytics needs that you have. So you’re cleansing this data and structuring the data for analytics and reporting, which is great. But the challenge with that, it takes a lot of maintenance, there’s a cost associated with that. And when you’re transforming that data, sometimes that can lead to quality-control challenges. It’s a little less flexible and agile.
So what’s become popular nowadays are these data lake houses. They’re sort of the best of both worlds. And so the idea is you’re still parking your data, but you can add some sort of structured reporting layer on top of that, where it doesn’t require you to duplicate all that data again into a separate database. So that gives you that agility and the flexibility to find that data on the fly, and gives you really two methods of exploring the data. On the maybe data lake side of the house, you can go ahead and have your data scientists explore the data there, and then your BI team can still use more the structured approach. So it’s really the best of both worlds, and that term is becoming a lot more popular.
When it comes to data pipelines, think of it as just a mechanism or method to collect data from all these different data sources, and then move them from all these data sources into your data lake or data warehouse or lake house, whatever you want to call it. It’s the method of moving it. It’s going to store that data centrally in a location. Now that data can be transformed as well. It’ll transform that data from raw data into a data that’s available and ready to use either for analytics or applications or even machine learning and AI. So the thing about data pipelines is that there’s a lot of different supported connectors and different types of pipelines out there. Some are vendor supported, which we’ll talk about here later in the presentation, but some can also be custom scripted via maybe using an API method or something like that. So these data pipelines are important because that’s the mechanism you’re going to use to move your data and then centralize it all in your data lake house.
So what are the benefits of this, and why should you care about doing this? As I mentioned with our Tableau clients, we hear this a lot: “We have all these different data sources; how do we pull this together?” Currently, we need to blend our data. And as you know, blending data in Tableau is great, flexible, it’s quick to do, but it has its own limitations, too, in terms of how much data you can usually blend together in Tableau desktop or prep. And also there’s a performance impact sometimes with that as well.
So anytime you have the opportunity to centralize your data in a single place, that’s always a good idea to do, and that’s where the data lake or data lake house comes into play. So you would create a pipeline, and the benefit is that you’re going to now have all your raw data in one place, and that’s also going to give you more agility. Because, as you all know, when you’re starting a project, there’s a lot of requirements up front. You’re trying to determine what data you need and things like that. You are collecting all the data now, and you are sourcing that data, and then you can go ahead and explore it later as you start building out your reporting layer versus spending all the time up front in the build process of your data lake. So that gives you a lot more flexibility, and it’s going to be a lot less maintenance, too, than maybe a traditional data warehouse. That gives you quicker time to insights. As I mentioned, you won’t have to do the blending in Tableau in your reporting layer, and you’re just going to be able to build your dashboards faster, because now you don’t struggle with some of those joins that maybe always cause you problems. So all these are the benefits that you’ll see by sort of having this combination of data lakes and data pipelines.
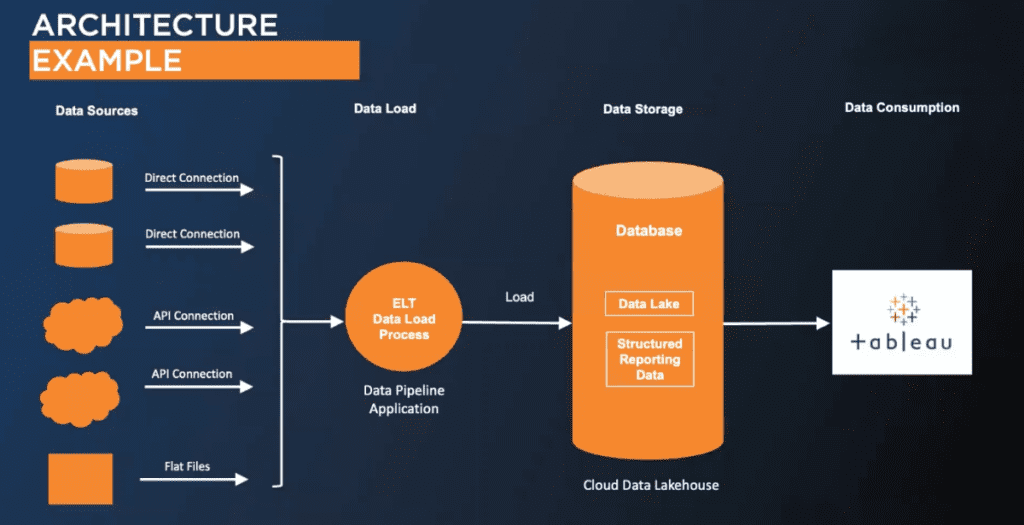
Here’s a diagram just to give you a visual representation of, when we talk about these things, data lakes and data pipelines, what is that? So this is an example architecture. Across the top, we have left to right, our data sources, and then we have a data load process, and then we’re storing the data, and then we’re consuming it in the reporting layer in Tableau. So with our data sources, those data sources, as I mentioned, can be anything from on-prem internal data sources that you have; maybe it’s an Oracle system or Teradata or some other place you’re pulling data from. It could be in the cloud. A great example that we see is Salesforce; that’s a perfect example to pull in. Or it could be flat files. They could be some sort of data extract or something that you’re provided maybe from a third-party vendor through an SFTP site.
All these sort of data sources need to be consolidated, and you would pull those in using data pipelines. And those pipelines, as I mentioned, could be custom, scripts, or they could be these vendor tools which we’ll touch on later. And these connectors are used to go ahead and ingest the data into your database, which is there in the middle. And that’s going to be preferably in the cloud. That’s really the movement where a lot of places are going. There’s a lot of great cloud platforms out there: Snowflake, Databricks, BigQuery, things like that, and people are moving their data there. So you’ll move your data into your data lake and then still maintain that reporting layer for production use and consumption with Tableau. So that’s what example architecture looks like.
Stuart, I don’t know if you have any other comments?
>> STUART: Yes. You know, when I look at this diagram, I see API connections. We’ve had a lot of clients in the past that have the more common applications. They might use NetSuite or QuickBooks and Salesforce, and all those sort of applications exist in the third-party pipeline tools. But every now and then is an application that is trickier to connect to, but they offer an API. And that’s a good representation here, Chris, where we’ve had many situations where, with that API documentation, we can build a connector that can flow into the data lake. So that’s a common request that we see for some of the more unique data sources out there.
>> CHRIS: Yes. Yes, for sure. And I think going back and talking about salesforce, there’s a lot of connectors that are supported out of the box with Tableau. And I know especially when people are just getting started, they tend to connect to those. But once they start connecting two or three of those and blending them together, they do see sometimes that it’s going to scale a lot better and be more performant if they do consolidate that data. So even something as common as Salesforce, which has a very good connector into Tableau, it’s going to be easier to consume that data if you go ahead and put it into, like, a data lake or some central repository.
So I guess we’ve laid out what a data lake and a data pipeline is, and the benefits of doing this. I think now it comes down to, how do you go about selecting a tech stack? And tech stacks, there’s just so many vendors out there. There’s many, many options, and here’s just a few. There’s probably 100 more. But one common trend among them all is a lot of them are in the cloud. Some support both on-prem and the cloud, so there’s a lot of things that when you’re evaluating and trying to pick your tech stack that you want to consider in order to make a good purchasing decision.
One of the things we wanted to put together is when you’re looking at a data lake or a database, for that matter, platform and a data pipeline, what are some of the most common things we hear during the evaluation process? So I think with any sort of database, it’s important to talk about the hosting. Are you going to host that on-prem within your corporate network or is this going to be cloud based? There is a huge trend to go to the cloud, but there are some business use cases and justifications why people like keeping that in-house. So that’s something you definitely want to consider.
Especially when it comes to cloud data lakes, you want to understand the cost. So one is, what is that pricing structure look like, and how much is it going to cost, from a resource standpoint, to maintain the system and the platform? When it comes to the pricing structure, a lot of the pricing structures are more geared nowadays toward compute and storage, and then some other variables. So some of them are real heavy on compute, and that’s where it can really cost you. But under certain circumstances, that compute cost might be worth it because it’s easier to use.
For example, we have some folks that use a certain platform and it is based off a compute, but their jobs only run frequently in the morning; they’re not doing real time during the day. So the flexibility of having an easy-to-use platform that they can train their resources on quickly and bring them up to speed is worth some of the pricing costs around compute, and vice versa. We have some other ones that are maybe a little bit more challenging to use, but the pricing model is a little more flexible. So all those are types of things that you need to evaluate when it comes down to costs.
You obviously want to understand the performance and scalability going to meet your SLAs, and we’ll talk about that here in a few slides. But you want to trial it and understand, is this going to scale for your organization? How much data do you think you’re going to store, and will this support it? Does it meet your security standards? That’s very important as well. There’s a lot of HIPAA out there, a lot of compliance standards that people need to meet, and you need to understand the nuances between them and make sure that they’re encrypting at rest, how they store their data, and make sure that it meets your corporate standards.
Lastly, I touched on the ease of use. That’s very important because most likely you’re moving to a new platform and you don’t have these skill sets in-house and you’re going to have to train your resources. So how do you go about doing that? And is it something that they can pick up quickly or is it going to take the better part of six months to a year to get proficient in it? So these are the things that we commonly hear and tell people to look for when they’re evaluating a new data lake environment or platform.
Stuart, did you have anything else to add to that?
>> STUART: No, I think that’s a great summary. Maybe something on this slide, but, yes, keep going.
>> CHRIS: Yes. So from a data pipeline side, very similar types of things. Obviously you want to understand performance and scalability, ease of use. But on the pipeline side of things, the connectors are really important, obviously. As we mentioned, a lot of these vendors out there today support various connectors. And so when you’re evaluating a vendor, you want to understand how many connectors they support, and what types of connectors they support. Most importantly, you want to make sure that they support all the ones that you have in your use case.
We do sometimes see that people use a combination of two vendors. That’s an OK option as well. But when you evaluate a vendor, you want to make sure not only do they have it on the list, but how well they support that connector. Some are better at it than others. You’ll find that some are community supported and some are supported directly by the vendor. So it’s very important to dig into the details of how long the connector has been around. How well has it performed, and then what’s the likelihood of it getting updated? Also, do you support custom connectors?
As Stuart mentioned, there’s a lot of different applications that we connect to. Of course out-of-the-box ones that most vendors support are going to be your NetSuites, your Salesforces, but you’re going to get more obscure ones that maybe aren’t supported directly and they require an API to connect to. So, like, Toast, for example, is very popular in the restaurant industry, but there’s not as many vendors supporting that, so sometimes we have to write a connector for that. And you want to make sure that that platform can support these custom connectors.
When it comes to support itself from the vendor, you want to make sure that they have good technical support, and you want to understand their SLAs. Because nothing’s worse than running an ETL load or data load on a Monday morning, or Sunday, even on the weekend, and having it fail, and having no one to reach out to, right? So you need to understand these SLAs, because this is your data. You have to support your business, and you need to understand what the turnaround time is going to be.
Lastly, I would say, when it comes to a lot of these data pipeline or platforms, cost varies between them. For some, the pricing structure is based on compute. So you spin up an instance, and as long as that instance is running, then that’s the price you pay. That works great for maybe certain scenarios where you’re processing a lot of records and you feel like you can do it quickly. In other cases you might want to go based on the number of records, and sometimes, that differs. That could be total records that are being updated, or it could be the difference in records, it could be the differential in updates on a daily basis. So it just varies from vendor to vendor. But you want to understand the nuances there because it can quickly scale or get out of hand on pricing if you don’t understand the nuances between that, how to refresh your entire NetSuite environment. So that’s something very, very important that you want to understand when you’re making your evaluation. All right.
So putting this all together, when you’re making your purchasing recommendations, we tell people that follow these basic steps. You want to go ahead and first identify all your data sources for current and future use cases. Make a list of just all of them that you currently need, your NetSuites, your Salesforces, and then any future ones that you feel you might need, and that’ll help you to, again, look at the vendors connector portfolio to see what they support. Then list all the requirements that are both important to you and also the business; the IT and the business. So you want to understand what are the one SLAs, what are the refresh times that they need, the refresh frequency that they need, and all that will start to factor into the cost. So gather all that information, and then select two to three vendors, and perform a trial.
Now, this is important because all the vendors allow you to do some sort of trial; and, again, because some of them are based on compute, or with the data pipelines, they’re also based on the volume of data you’re moving. It’s important to do this trial because during this trial period, typically, it’s free to load that data, and that way, you can start to see a pattern and understand what your daily volume is going to look like, and you can then start to estimate your costs. So I highly recommend a trial. That’s going to be the best way for you to understand your future costs, and then you can budget for that for the year.
Another thing, too, is that you can pre-purchase credits. So when it comes to compute, you can pre-purchase credits, and that way, that’ll give you a little bit of a discount up front on any of that cost. And so that’s another great way to just understand what that discount model look like when you’re talking to a vendor. The pricing structure and the maintenance costs is all that you need to factor in, and the maintenance, of course, also being your resources. How much support and how many resources do you think are going to be needed for this new platform?
We do find that with the data pipelines, they’re very efficient, especially for some of our smaller organizations that we work with. It saves them a lot of time, and pretty much a full resource. In the past, back in the old days, probably dating myself, you used to have to have a whole team that supported a lot of these data pipelines, and now it’s simple point and click, a fractional part of someone’s job. So it’s a huge savings to go ahead and move obviously to this type of model, and that’s why we highly recommend it.
During your purchasing process, create a project plan, understand what the rollout and timeline is going to look like. And then, of course, purchase training and certifications for your team, and then go ahead and deploy, and everything should run pretty smoothly.
So yes, that’s really, high level, what considerations to make when you’re making your purchase. And following these steps, we’ve seen a lot of successful rollouts of data lakes and data pipelines.
>> STUART: One thought, too, on the previous slide. We have a lot of clients that have lots of data sources, and these data lake projects work really well in a phased approach as well. A lot of our clients will isolate the key data sources that they want to generate key reports off of, and they kind of, in a phase two or three, will bring in the whole list of data. So it doesn’t necessarily have to be done all at once. Would you agree, Chris?
>> CHRIS: Yes, I definitely would agree with that. That’s a fair statement, for sure. Cool. Well, so with that, I will say that if you have any questions about this, or just where to get started just in this process, or even want some guidance or recommendations on maybe some different platforms we’ve seen, feel free to reach out to myself or Stuart. We’ll be happy to set up a quick call and just chat with you.
Stuart, let’s open it up to some Q&A here.
>> STUART: Yes, we had a few questions that came in. So one was asked: “What about data out of Tableau to your systems so that another entity can access data?” So what data out of Tableau to your system, so that another entity can access it? Any thoughts on that, Chris?
>> CHRIS: Yes, I wouldn’t say that that’s something that we typically do a lot of. I’m trying to think of an instance where we’ve done that. It depends how this data source is being created. Obviously, if this data source is something that you’ve created using Tableau prep, and publishing this data source, you can configure that prep flow to maybe push that data into a table or somewhere else that could be consumed. You could also use the APIs to retrieve that data. So Tableau has a very robust API. You can use Python or something to go ahead and retrieve the result sets from this data source and put it on a refresh. So that would sort of be the approach I would try there.
>> STUART: And then someone asked about, they’re only familiar with using Azure and SQL Server and Power BI. A little bit of experience there, but any thoughts on how that might translate to other tools out there?
My thought on that question is that, correct me if I’m wrong, Chris, but a lot of the data lake technology, the vendors that are out there, it’s relational based, so SQL works very well. Having that experience would translate well to other tools outside of Microsoft Azure.
CHRIS: Yes. I think if you’re mainly on a Microsoft stack, I think what I’ve seen, especially with some other platforms like Snowflake, for example, it’s very easy to use, and we’ve seen a lot of people easily move from a SQL Server background into using Snowflake, so that transition was really easy for them. You know, these tools are great as well. Obviously, we’re pretty partial to Tableau, but I think if you’re on a stack like that, making a transition to some of the other vendors that we’ve mentioned here, there’s a lot of commonality between the two, and we’ve seen people do that jump pretty easy.
STUART: One question we get a lot is, “How long does it take to get a data lake set up, and to get data in there?” Do you have any thoughts on that, Chris?
>> CHRIS: Yes. Like all things in life, it depends. I think the most things that factor into it is, how many different connections are you going to have? How many different data sources are you pulling together? And the reason being is; one, there’s the level of effort to create the pipelines. Are any of them custom? That factors into it as well. And then how do you blend those data sources together on the database side?
So that’s something we didn’t touch on here because it’s a little more technical. But if you think of your different systems, let’s just take two: NetSuite, Salesforce, one needs to be sort of the system of record, and you might have a master product hierarchy, or even a customer hierarchy, or even your employee hierarchy. And so that needs to be standardized, and those IDs from one system needs to be also stored in the other, or some sort of mapping table. So there’s some work involved in that as well.
I think we do some engagements here that are as quick as a week, a week and a half, and that’s more for smaller, departmental, even some larger companies that only have a couple of data sources. And it just really depends on the level of reporting that they need. But, again, a larger project, of course, could take several months for a first phase. So it just really varies on the number of connectors. I don’t know, Stuart, if…
>> STUART: Yes.
>> CHRIS: You see a lot more on the sales side, a lot of requests. What are some of the factors you see that variable is there?
>> STUART: Yes, I think you definitely hit on a few. The third-party data pipeline platforms that are out there have made it so simple, so quick to load data. So that is awesome. Those products exist and it’s really quick to get data in. We see, when clients do have these custom applications, that you have to write some code to get the data in, and that can take a little longer. But as generally, I’ve seen it’s very fast to get data lake stood up. Now the warehousing part of it, to get it more curated and more organized for reporting can take that sort of a work in progress, and can take more time, but generally very fast.
CHRIS: Yes, I would say from a development standpoint, like some of the shorter ones that we’ve done, which are just a few weeks. I would say a couple of weeks, even, in actual level of effort, by the time you trial and select a platform… We have our own recommendations, but sometimes people want to try different ones as well. By the time you go through that vendor selection process and trial it, it can be the better part of three to four weeks, and then a couple of weeks in duration for development. So anywhere from six to eight weeks to get something going sometimes.
STUART: Another question that we get all the time is, “How do we know if we need to have a data lake?” I’ve got a few thoughts, but if you want to take it first, Chris.
>> CHRIS: Yes, that’s a great question. Well, I do know, from a reporting standpoint, you’ll start to hear your developers say that it’s taking a long time to do the type of reports they want to build. The analytics that they want to do, the aggregations they want to do, maybe the data stored at different levels of aggregation, they don’t join properly, they might be using Tableau prep a lot. When you start hearing that stuff, they’re doing too much heavy lifting on the data side, and it’s time to consider consolidating your data. But even before that, I think if you hear a lot of your business just talking about all the different data sources that they have, you’ve probably outgrown just having these siloed systems, and it does make sense to have some sort of central data lake or lake house.
STUART: Yes. I would say, too, a lot of times we’ll have clients that they want to connect to data that Tableau just doesn’t have a supported connector, so that can be a big indicator. And they certainly want it to be automated, so taking exports can be taxing and frustrating to some degree, and that’s usually a good indicator. There are other data pipeline tools that might offer that connector, and many more that a client has, and that’s a good barometer to say, “OK, well we could set up a data lake, and have all that data centrally located and optimized.” That’s a big indicator that I see.
>> CHRIS: Yes, that’s a good point. I think something that maybe wasn’t necessarily called out on these slides is, there’s an automation to all this, and that’s really what you’re trying to do here. If you find that your teams are constantly doing data pools and stuff like that, there’s a better way to do it. And go ahead and use these custom APIs or find a way to automate it, and that’s going to be a huge savings.
>> STUART: Yes. A question came in: “Where do you see a formal enterprise data governance program fitting into the data lake and pipeline process?” So what point in the setup process do you recommend data governance?
>> CHRIS: Oh, that’s a good question. I guess I would say, early on, obviously, you want to keep data governance in mind. We always make sure that only certain people are stewards of the data. We don’t want everybody creating these data pipelines, and creating a bigger problem by putting everything into your data lake house. So you want to have a proper data governance strategy early on, right out the gate, even if it’s on a smaller departmental level. It doesn’t have to be something super formal, but have the processes in place of who is allowed to pull in certain tables, who’s allowed to make those changes to your data pipelines and make those changes to the lake house. Who has access to sensitive data, right? All that needs to happen upfront. So I would do that very early on in the process, and just get that as part of your culture.
>> STUART: Yes. Another question came in, Chris. This organization has several third-party data sources. They want to harmonize them. They only have an on-prem SQL Server, which is used as a warehouse. Do they need a data lake is the question.
>> CHRIS: Oh. So they only have one source, which is SQL Server.
>> STUART: It sounds like there are multiple third-party data sources, but they currently do have an on-prem SQL Server, presumably, that data goes into.
>> CHRIS: Yes. So we’ve had this scenario before, and we find that just with some of these pipeline tools that are out there, it’s easier than using maybe your traditional tools like maybe an SSIS or something like that to pull it back into SQL Server. Try to modernize. And if the thought is moving more to the cloud, anyway, and moving off that SQL Server, then I would make the jump sooner than later. That would be my recommendation. So that’s what we’ve done with a lot of clients.
Certain platforms like Fivetran, for example, they have a SQL Server connector, and you can configure it to reach into your on-prem SQL Server, and ingest that data into Fivetran, and move it to Snowflake or somewhere. So we do that all the time. That’s a very common use case.
>> STUART: There was a clarification here that they have many sources that they buy, but only one of them goes into that SQL Server database. I would say yes to a data lake. And they said, “For example, we buy data from Broadridge, SS&C, RIA database, but only the SS&C data goes to that warehouse. So data lake might be a great option to get all that data centralized in one place for easier reporting. I would say yes.
>> CHRIS: Yes, I would too. Yes.
>> STUART: Yes. Good question. Someone else just asked, and it’s a good question to come back up again, but just the difference between data lake, lake house, and data warehouse. Chris, do you want to maybe flip back to that slide one more time? Because this is certainly a good question and a topic that comes up a lot.
>> CHRIS: Yes, we’ll cover this slide one more time. So if you think of a data lake being more like a parking lot, where you’re going to put more of your raw data. You’re not really sure what you want to use it for. You park it there, and it can be explored later. You’re not transforming it at this point; just parking it there. That’s going to be your data lake. That data can be, again, in different formats; structured, unstructured, semi structured, that kind of thing. But it’s not necessarily modeled into a proper schema or anything like that.
With a data warehouse, it’s going to be more defined. So you’re going to talk to the business, understand the KPIs they want, and then you would build out a proper schema or data model that supports these analytics that you want to run as a company. So you would build the dimensions and maintain all this, and ensure data quality as well. But that takes a lot of labor and a lot of time to build these data warehouses.
As I mentioned, there’s something in between now where it gives you a little bit of both flexibility, where you can store that data now and then go ahead and build these reporting layers. Then you can go ahead, and rather than reduplicating all your data into a data warehouse, you can do that right there in your data lake and lake house and report. And that way, your data science team can explore the raw data because they’re trying to identify, maybe, certain nuggets out of that data. And then your analytics team that still needs those proper definitions for reporting purposes still have that as well. So that’s sort of the differences there.
>> STUART: Yes. All right. It looks like all the questions we have. Anyone else have any last-minute questions here? I think we got to them all.
>> CHRIS: All right. Well, again, thank you, everyone, for joining us. If you have any questions, of course, we’ll be happy to answer them. Just drop us an email, me or Stuart. We’d be happy to answer an email or hop on a quick call. But thank you all for joining, and we will see you next month at our next DDC event. Take care.
>> STUART: Thanks, everyone.
